Integrate CrewAI with LangGraph for Designing Agent Based LLM Pipeline Along with LLAMA2 Based Few-Shot Prompting for LLM Based Evaluation of Generated Content
Why Do we LangGraph?
Langchain is good for building LLM pipelines ,but it can build only DAG (Directed Acyclic Graph) which means it does not have any cycles.This means if we want to include any kind of feedback loop it is not feasible using Langchain.
Why Do we need a Feedback Loop?
While we design LLM pipelines we need a mechanism to judge the output generated by LLM.This judging or scoring of the output can be either by a Human in the Loop or LLM-based or Rule-Based.
According to the score or judgement returned by the feedback module we can make the LLM to modify the prompts (HyDE) or force RAG based LLM architecture to pick more appropriate samples.
Importance of LangGraph:
LangGraph is a framework which is capable of using the Langchain functions along with external functions which is python based.The main advantage of LangGraph is that it can have cycles in it.
That means in a LLM pipeline written in LangGraph we can have feedback loops which will enable the pipeline to exploit Human-Based,Rule-Based or LLM-Based Feedback to optimize the prompts or pick up better few-shot samples to make the LLM pipeline more optimized for the specific use-case.
LangGraph is framework agnostic (each node is a regular python function). It extends the core Runnable API (shared interface for streaming, async, and batch calls) to make it easy to:
- Seamless state management across multiple turns of conversation or tool usage
- The ability to flexibly route between nodes based on dynamic criteria
- Smooth switching between LLMs and human intervention
- Persistence for long-running, multi-session applications
What is CrewAI?
Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.
CrewAI constitutes of following components:
1.Agents
2.Tasks
3.Tools
4.Processes
5.Crews
6.Collaboration
7.Memory
To Understand mote about the following components please refer to the documentation link: https://docs.crewai.com/core-concepts/Agents/
Integrate LangGraph with CrewAI:
In this article we will integrate LangGraph with CrewAI so that we can use the Feedback Loop of LangGraph along with the power of LLM Pipeline using LangChain and other python APIs and use CrewAI agents as nodes in LangGraph so that wherever required we can use leverage the agents in our LLM pipeline for diffrent kinds of external activities like Web Search, Writing Mails, building Web Pages and so on.
We will use the state-space model of LangGraph to keep the LLM outputs,search articles urls and parsed content as states of the LangGraph which will be persisted across sessions and on the other hand we will use CrewAI’s easy integration with different types of functionalities like web-search,Instagram Handle,Mailing components.
Install Necessary Packages:
pip3 install langchain
pip3 install langchain_community
pip3 install langchain-core
pip3 install langgraph
pip3 install transformers
pip3 install ipykernel
pip3 install sentence-transformers
pip3 install bs4
pip3 install google-api-python-client>=2.100.0
pip3 install chromadb
pip3 install html2text
pip3 install playwright
######Agents Framework #################
pip3 install crewaiInstall python package for Visualization of LangGraph Pipeline:
sudo apt-get install python3-dev graphviz libgraphviz-dev pkg-config
pip install graphviz
pip install pygraphvizDefine the LLM That will be Used for of the LangGraph Workflow Pipeline:
from langchain_community.chat_models import ChatOllama
local_llm = "llama2:latest"
#local_llm = ""
llm = ChatOllama(model=local_llm, temperature=0)Define the Search Utility That will be Used for Searching the Web for getting information about the User Query [Note:In this use case we have used GoogleSearchAPIWrapper]
import os
from langchain.utilities import GoogleSearchAPIWrapper
##API Key
os.environ["GOOGLE_CSE_ID"] = "XXXXXXX"
os.environ["GOOGLE_API_KEY"] = "XXXXXXXXX"
search = GoogleSearchAPIWrapper(k=5)Define the Embedding Model and VectorStore for Similarity or MMR Based Search:
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import LlamaCppEmbeddings
import nest_asyncio
from tqdm import tqdm
from langchain_core.documents import Document
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain_text_splitters import RecursiveCharacterTextSplitter
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2",model_kwargs = model_kwargs)
vectorstore = Chroma(embedding_function=embeddings, persist_directory="./chroma_db_instance1")
chunk_size=2000Define the Function That will be Used for Scraping Data from HTML page:
nest_asyncio.apply()
#URL SCRAPING
def scrape_with_playwright(urls, bs4=True, tags=["span"], log=False):
loader = AsyncChromiumLoader(urls)
docs = loader.load()
if bs4:
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=tags,
)
else:
docs_transformed = docs
return docs_transformedDefine the Function That will be Used for Scraping Data from PDF documents:
##PDF SCRAPING LIBRARIES
from langchain_community.document_loaders import PDFMinerLoader,PyPDFLoader,PDFMinerPDFasHTMLLoader
import re
from langchain_community.docstore.document import Document
#PDF SCRAPING
##PDFMinerLoader###
def scrape_pdf_PDFMiner(url):
loader = PDFMinerPDFasHTMLLoader(url)
data = loader.load()[0]
from bs4 import BeautifulSoup
soup = BeautifulSoup(data.page_content,'html.parser')
content = soup.find_all('div')
cur_fs = None
cur_text = ''
snippets = [] # first collect all snippets that have the same font size
for c in content:
sp = c.find('span')
if not sp:
continue
st = sp.get('style')
if not st:
continue
fs = re.findall('font-size:(\d+)px',st)
if not fs:
continue
fs = int(fs[0])
if not cur_fs:
cur_fs = fs
if fs == cur_fs:
cur_text += c.text
else:
snippets.append((cur_text,cur_fs))
cur_fs = fs
cur_text = c.text
snippets.append((cur_text,cur_fs))
# Note: The above logic is very straightforward. One can also add more strategies such as removing duplicate snippets (as
# headers/footers in a PDF appear on multiple pages so if we find duplicates it's safe to assume that it is redundant info)
#print('SNIPPETS:')
#print(snippets)
cur_idx = -1
semantic_snippets = []
# Assumption: headings have higher font size than their respective content
for s in snippets:
# if current snippet's font size > previous section's heading => it is a new heading
if not semantic_snippets or s[1] > semantic_snippets[cur_idx].metadata['heading_font']:
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
continue
# if current snippet's font size <= previous section's content => content belongs to the same section (one can also create
# a tree like structure for sub sections if needed but that may require some more thinking and may be data specific)
if not semantic_snippets[cur_idx].metadata['content_font'] or s[1] <= semantic_snippets[cur_idx].metadata['content_font']:
semantic_snippets[cur_idx].page_content += s[0]
semantic_snippets[cur_idx].metadata['content_font'] = max(s[1], semantic_snippets[cur_idx].metadata['content_font'])
continue
# if current snippet's font size > previous section's content but less than previous section's heading than also make a new
# section (e.g. title of a PDF will have the highest font size but we don't want it to subsume all sections)
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
return semantic_snippetsDefine Function for Fetching and Scraping Web Page Content:
#Defining the Retriever fot Merging the Results of Different Retriever to Prevent Duplicate Information and Contextual Compression
from langchain.retrievers import (
ContextualCompressionRetriever,
#DocumentCompressorPipeline,
MergerRetriever,
)
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import (
EmbeddingsClusteringFilter,
EmbeddingsRedundantFilter,
LongContextReorder
)
def fetch_and_scrape_pages(input,top_n):
search = GoogleSearchAPIWrapper()
nest_asyncio.apply()
results = []
search_results = search.results(input, top_n)
#print(search_results)
for result in tqdm(search_results):
#if 'https://www.espncricinfo.com/series/ipl/' in result:
try:
source = result.get("link", "None")
if source.find(".pdf") != -1:
docs = scrape_pdf_PDFMiner(source)
results = results + docs
else:
pages_content = scrape_with_playwright([source])
results = results + pages_content
except Exception as e:
print(f"Failed to scrape url: {source} with Exception {e}")
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size, chunk_overlap=400 #added chunk overlap of 10 percent as a part of best practice
)
result_chunks = splitter.split_documents(results)
return result_chunksDefine Function for Loading and Searching VectorStores in ChromaDB:
#Load ChromaDB
def load_vectorstore_chroma(db, embeddings, docs, persist=False):
ids = db.get()['ids']
print(docs)
if len(ids)>0:
db.delete(
ids=ids
)
db = Chroma.from_documents(docs, embeddings, persist_directory="./chroma_db_instance1")
return db
# Similarity Based Search
def search_vectorstore_chroma(db,query):
docs = db.similarity_search(query,k=20)
return docs
# MMR Based Search
def search_vectorstore_chroma_hybrid_retriever(db,embeddings,query):
#db = Chroma(persist_directory="./chroma_db_oai", embedding_function=embeddings)
retriever_sim = db.as_retriever(
search_type="similarity", search_kwargs={"k": 20}
)
retriever_mmr = db.as_retriever(
search_type="mmr", search_kwargs={"k": 20}
)
merger = MergerRetriever(retrievers=[retriever_sim, retriever_mmr])
filter = EmbeddingsRedundantFilter(embeddings=embeddings)
reordering = LongContextReorder()
pipeline = DocumentCompressorPipeline(transformers=[filter, reordering])
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline, base_retriever=merger
)
docs=compression_retriever.get_relevant_documents(query)
return docsDefine the Python Function that will act as a single point of Call for LangGraph:
def web_searcher(query,vectorstore,embeddings):
results = fetch_and_scrape_pages(query,10)
similar_docs=[{"content": "'''"+ result.page_content + "'''"} for result in results]
#print('chunked results')
#print(similar_docs)
#vs = load_vectorstore_chroma(vectorstore,embeddings,results)
#similar_docs=search_vectorstore_chroma_hybrid_retriever(vectorstore,embeddings,query)
#print("SIMILAR DOCS:")
#print(similar_docs)
return similar_docsConstruct the Dictionary that will persist the States for the State-Space Machine of LangGraph and Define the Data-Types for the various State Variables that will be persisted:
from typing import TypedDict, Annotated, Sequence, Dict, List
import operator
from langchain_core.messages import BaseMessage
from IPython.display import Image
class IPLGraphState(TypedDict):
question: str
parsed_content_lst: List[Dict]
task: str
summary: str[Note: The Variable data-type type must abide the allowed pydantic data types]
Construct the Functions for each LangGraph Node:
import json
import operator
from typing import Annotated, Sequence, TypedDict
from langchain import hub
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import Chroma
from langchain_core.messages import BaseMessage, FunctionMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.output_parsers import StrOutputParser
### Nodes ###
def task_decider(state):
"""
Determines which type pf task needs to be executed based on user's query.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with relevant documents
"""
print("---CHECK FUNCTION TO BE CALLED---")
#state_dict = state["keys"]
question = state["question"]
# Prompt
prompt = PromptTemplate(
template="You are a supervisor tasked with managing user requests in form of conversation"
"Given a user request: \n\n {question} \n\n select the task type it should belong to"
"The task type can be one among : summarizer, graph_builder"
"Only Return one of these two words i/e. summarizer or graph_builder in the output and nothing else",
input_variables=["question"],
)
# Chain
chain = prompt | llm | StrOutputParser()
#for d in documents:
score = chain.invoke(
{
"question": question,
}
)
#grade = score["score"]
print(score)
print("GRADE")
print(score)
if "summarizer" in score.lower():
print("---AGENT: Summarizer---")
task='summarizer'
#filtered_docs.append(documents)
#print(documents)
else:
print("---AGENT: GraphBuilder---")
task='graph_builder'
#continue
state["task"]=task
return state
def search_parse(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
#state_dict = state["keys"]
question = state["question"]
task=state["task"]
#embeddings=state_dict["embeddings"]
#vectorstore=state_dict["vectorstore"]
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2",model_kwargs = model_kwargs)
vectorstore = Chroma(embedding_function=embeddings, persist_directory="./chroma_db_instance1")
#documents = retriever.get_relevant_documents(question)
#meta_lst = web_searcher(question)
parsed_content_lst=web_searcher(question,vectorstore,embeddings)
state["parsed_content_lst"]=parsed_content_lst
return state
def query_transformer(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
#state_dict = state["keys"]
question = state["question"]
summary = state["summary"]
task=state["task"]
# LLM
#llm = ChatOllama(model=local_llm, temperature=0)
# Create a prompt template with format instructions and the query
prompt = PromptTemplate(
template="""You are generating question that will make the summary more informative. \n
Analyze the user_question along with the generated_summary and try to find what information is lacking in summary.\n
Also find out whether the information in generated_summary is about Indian Premier League for the specific year
matches to the year mentioned in the user_question. \n
If year or tournament name is not matching the question rewrite the question in such a way
that it queries the correct tournament and year.\n
If the year of the tournament in generated_summary is matching to user_question then
generate question that will ask for outcome of the tournament.
Generate only a single question.
The output should only contain the rewritten question and nothing else.
user_question:
\n ------- \n
{question}
\n ------- \n
generated_summary:
\n ------- \n
{summary}
\n ------- \n
""",
input_variables=["question","summary"],
)
# Chain
chain = prompt | llm | StrOutputParser()
better_question = chain.invoke({"question": question,"summary":summary})
print('REWRITTEN QUESTION:')
print(better_question)
state["question"]=better_question.replace('Rewritten question: ','')
return stateConstruct the CrewAI Agent and Task for Summarization:
from crewai import Task
from textwrap import dedent
from crewai import Agent, Task, Crew
class ContentGenerationAgents():
def summary_agent(self):
return Agent(
role='Principal Sports Journalist',
goal=
'Carry out Informative and concise summaries based on the content you are working with',
backstory=
"""
You're a Principal Sports Jounalist of a big Company Like Star Sports who specilaizes in Indian Premier League.\n
You can precisely write highlights about any Indian Premier League tournament for the year mentioned in the question.\n
While writing summary you focus on the outcome of final match, players statistics of top batsman and bowler,\n
number of matches played,best performers in the knockout matches etc. \n
While writing summary focus only on the year of the IPL mentioned in the question.
""",
allow_delegation=False,
llm=llm,
max_iterations=1,
verbose=True
)
class ContentGenerationTasks:
def summary_task(self, agent, content):
#print(content)
return Task(
agent=agent,
description="Analyze and summarize the content below and make sure that the summary is constructed"
"using only the information in the below content.Do not make up any information using your "
"existing knowledge.The summary should contain the details like tournament start ,end date."
"The summary must also contain details like outcome of the tournament and statistics of"
"top performing players."
"If the user is asking for the summary of IPL of some specified year which is outside of your knowledge"
"Try to use the content provided below to come up with the summary for a match which you"
"dont have in your knowledge"
"return only the summary nothing else."
f"\n\ncontent:\n----------\n{content}",
expected_output="give a well summary of the content and try to keep it between 250-500 words.",
verbose=True
)Construct the CrewAI Crew Class which will define the __init__ and kickoff functions:
class SummarizerCrew():
def __init__(self):
agents = ContentGenerationAgents()
self.summary_agent = agents.summary_agent()
def kickoff(self, state):
print("Summarizing IPL Results")
#state_dict = state["keys"]
docs = state["parsed_content_lst"]
question = state["question"]
task = state["task"]
#print('Filtered Documents')
#print(documents)
scraped_data = ""
for doc in docs:
s = f"{doc['content']}.\n"
scraped_data += s
tasks = ContentGenerationTasks()
crew = Crew(
agents=[self.summary_agent],
tasks=[
tasks.summary_task(self.summary_agent, scraped_data)
],
verbose=True
)
result = crew.kickoff()
state['summary']=result
return {**state}The ‘kickoff’ function will be called along with Class Reference ‘SummarizerCrew().kickoff’ which will act as LangGraph Node.
This is the Step which is required CrewAI will be integrated with LangGraph.
Construct the LLAMA2 Few-Shot Prompting which will act as a LLM Based Evaluator for Grading Whether the Generated Summary is in Context With User Query:
from langchain_core.messages import HumanMessage,SystemMessage,AIMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
def grade_generation_summary_v2(state):
"""
Determines whether the generation addresses the question.
Args:
state (dict): The current state of the agent, including all keys.
Returns:
str: Binary decision
"""
print("---GRADE GENERATION SUMMARY vs QUESTION---")
#state_dict = state["keys"]
question = state["question"]
#documents = state["documents"]
summary = state["summary"]
#llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
few_shot_prompt = [
SystemMessage(content="""You are a sports jounalist assessing whether an answer is useful to resolve a question. \n
While analyzing the usefulness focus whether the tournament name and year matches exactly with the
user_question.\n
If the summary is containing information about multiple tournaments from different years then it is not useful,
grade it as 'no'.
The summary is useful only if it contains information about the specfic tournament for the specific
year mentioned in user_question ,in this case grade the summary as 'yes'. \n
Also focus on whether the final outcome of that tournament for the specific year is mentioned in the
summary or not. \n
Return only binary output 'yes' if it is useful or 'no' and nothing else.
"""),
HumanMessage(
content="""generated_summary:
'The Indian Premier League (IPL) season 15, held in 2022, was a thrilling tournament that saw some of the best cricketing teams and players compete against each other. The tournament began on April 9th, 2022, and concluded on May 30th, 2022. A total of 60 matches were played across various venues in India.
The final match of the season was played between the Mumbai Indians and the Delhi Capitals at the Rajiv Gandhi International Stadium in Uppal, Hyderabad. The Mumbai Indians emerged as the winners of the tournament after defeating the Delhi Capitals by 5 wickets.
In terms of player statistics, Virat Kohli of the Royal Challengers Bangalore was the top batsman of the season, scoring 738 runs in 14 matches at an average of 62.90 and a strike rate of 135.30. Meanwhile, Jasprit Bumrah of the Mumbai Indians was the top bowler of the season, taking 26 wickets in 14 matches at an average of 17.85 and an economy rate of 6.96.
The knockout stages of the tournament saw some exciting matches, with the Chennai Super Kings defeating the Sunrisers Hyderabad in the eliminator by 10 wickets, and the Rajasthan Royals defeating the Kolkata Knight Riders by 2 wickets in the qualifier.
The IPL 2022 season saw some impressive performances from debutants like Shimron Hetmyer of the Sunrisers Hyderabad and Suryakumar Yadav of the Mumbai Indians, who were named the Emerging Player of the Season.
Overall, the Indian Premier League season 15 was a thrilling tournament that saw some of the best cricketing teams
and players compete against each other. The final match between the Mumbai Indians and the Delhi Capitals was an
exciting encounter that saw the Mumbai Indians emerge as the winners.'
\n
user_question:
'Results of Indian Premier League 2019'
\n"""
),
AIMessage("""grade: 'no' """),
HumanMessage(content="""generated_summary:
'The Indian Premier League (IPL) season 15, held in 2022, was a thrilling tournament that saw some of the best cricketing teams and players compete against each other. The tournament began on April 9th, 2022, and concluded on May 30th, 2022. A total of 60 matches were played across various venues in India.
The final match of the season was played between the Mumbai Indians and the Delhi Capitals at the Rajiv Gandhi International Stadium in Uppal, Hyderabad. The Mumbai Indians emerged as the winners of the tournament after defeating the Delhi Capitals by 5 wickets.
In terms of player statistics, Virat Kohli of the Royal Challengers Bangalore was the top batsman of the season, scoring 738 runs in 14 matches at an average of 62.90 and a strike rate of 135.30. Meanwhile, Jasprit Bumrah of the Mumbai Indians was the top bowler of the season, taking 26 wickets in 14 matches at an average of 17.85 and an economy rate of 6.96.
The knockout stages of the tournament saw some exciting matches, with the Chennai Super Kings defeating the Sunrisers Hyderabad in the eliminator by 10 wickets, and the Rajasthan Royals defeating the Kolkata Knight Riders by 2 wickets in the qualifier.
The IPL 2022 season saw some impressive performances from debutants like Shimron Hetmyer of the Sunrisers Hyderabad and Suryakumar Yadav of the Mumbai Indians, who were named the Emerging Player of the Season.
Overall, the Indian Premier League season 15 was a thrilling tournament that saw some of the best cricketing teams
and players compete against each other. The final match between the Mumbai Indians and the Delhi Capitals was an
exciting encounter that saw the Mumbai Indians emerge as the winners.'
\n
user_question:
'Results of Indian Premier League 2022'
\n"""),
AIMessage("""grade: 'yes' """),
HumanMessage(
content="""generated_summary:
'The Indian Premier League (IPL) season 15, held in 2022, was a thrilling tournament that saw some of the best cricketing teams and players compete against each other. The tournament began on April 9th, 2022, and concluded on May 30th, 2022. A total of 60 matches were played across various venues in India.
The final match of the season was played between the Mumbai Indians and the Delhi Capitals at the Rajiv Gandhi International Stadium in Uppal, Hyderabad. The Mumbai Indians emerged as the winners of the tournament after defeating the Delhi Capitals by 5 wickets.
In terms of player statistics, Virat Kohli of the Royal Challengers Bangalore was the top batsman of the season, scoring 738 runs in 14 matches at an average of 62.90 and a strike rate of 135.30. Meanwhile, Jasprit Bumrah of the Mumbai Indians was the top bowler of the season, taking 26 wickets in 14 matches at an average of 17.85 and an economy rate of 6.96.
The knockout stages of the tournament saw some exciting matches, with the Chennai Super Kings defeating the Sunrisers Hyderabad in the eliminator by 10 wickets, and the Rajasthan Royals defeating the Kolkata Knight Riders by 2 wickets in the qualifier.
The IPL 2022 season saw some impressive performances from debutants like Shimron Hetmyer of the Sunrisers Hyderabad and Suryakumar Yadav of the Mumbai Indians, who were named the Emerging Player of the Season.
Overall, the Indian Premier League season 15 was a thrilling tournament that saw some of the best cricketing teams
and players compete against each other. The final match between the Mumbai Indians and the Delhi Capitals was an
exciting encounter that saw the Mumbai Indians emerge as the winners.'
\n
user_question:
'Results of Indian Premier League 2017'
\n"""
),
AIMessage("""grade: 'no' """),
]
few_shot_prompt.append(HumanMessage(content=""" generated_summary:"""+"'"+summary+"'"+"""\n"""\
""" user_question:"""+"'"+question+"'"+"""\n"""))
json_schema = {
"title": "Person",
"description": "Identifying information about a person.",
"type": "object",
"properties": {
"name": {"title": "Name", "description": "The person's name", "type": "string"},
"age": {"title": "Age", "description": "The person's age", "type": "integer"},
"fav_food": {
"title": "Fav Food",
"description": "The person's favorite food",
"type": "string",
},
},
"required": ["name", "age"],
}
prompt = ChatPromptTemplate.from_messages(few_shot_prompt)
print('FINAL PROMPT FOR LLAMA2:')
print(prompt)
dumps = json.dumps(json_schema, indent=2)
chain = prompt | llm | StrOutputParser()
result= chain.invoke({"dumps": dumps})
grade = result.split('[INST] <<SYS>><</SYS>>')[0]
print('SCORE RAW LLM OUTPUT:')
print(result)
if "yes" in grade.lower():
print("---DECISION: USEFUL---")
return "useful"
else:
print("---DECISION: NOT USEFUL---")
return "not useful"Construct the the Graph Workflow using LangGraph:
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(IPLGraphState)
# Define the nodes
workflow.add_node("task_decider", task_decider)
workflow.add_node("search_parse", search_parse) # search web & parse
workflow.add_node("query_transformer", query_transformer) # transform_queryMap the CrewAI Function to a LangGraph Node:
workflow.add_node("summarizer", SummarizerCrew().kickoff)Build the Graph Along with Feedback Loop which will either proceed towards Completion or move back to an existing Node based on the Feedback Decision:
# Build graph
workflow.set_entry_point("task_decider")
workflow.add_edge("task_decider", "search_parse")
workflow.add_edge("search_parse", "summarizer")
workflow.add_conditional_edges(
"summarizer",
grade_generation_summary_v2,
{
"useful": END,
"not useful": "query_transformer",
},
)
workflow.add_edge("query_transformer", "search_parse")
# Compile
app = workflow.compile()Over here the feedback loop will be governed on the output of the function grade_generation_summary_v2.If the output of the function grade_generation_summary_v2 contains ‘yes’ then the summarizer output will be considered as useful and the workflow will come to an end ,else it will go back to the “transform_query” node and it will transform the user search query and once again execute “search_parse” function which in turn will call the “summarizer” and this will go on until and unless grade_generation_summary_v2 function outputs ‘yes’.
View the LangGraph Nodes and Their Connections with the Feedback Loop:
from IPython.display import Image
Image(app.get_graph().draw_png())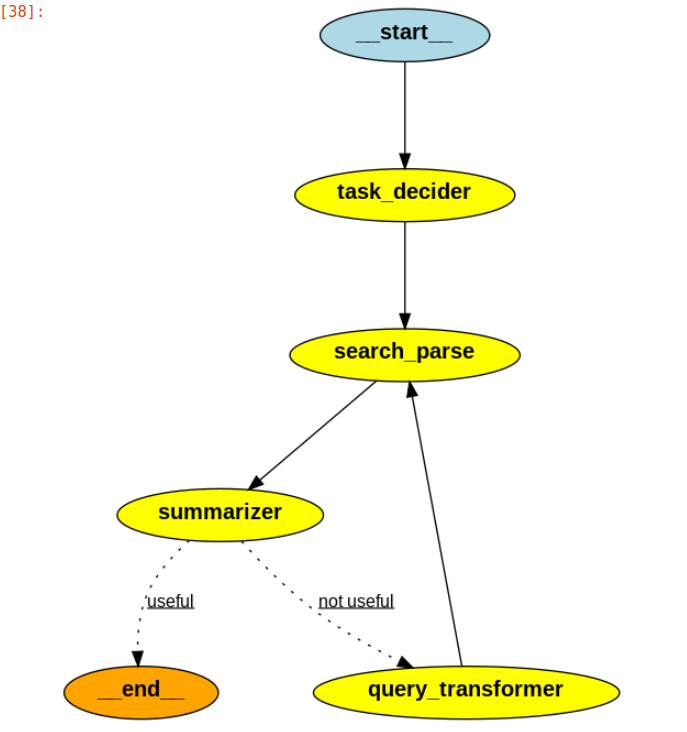
Execute the LangGraph Workflow:
# Run
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
#inputs = {"keys": {"question": "Results of The Indian Premier League of year 2018"}}
inputs = {"question": "Results of The Indian Premier League of year 2018"}
for output in app.stream(inputs):
for key, value in output.items():
print('Running')
#pprint.pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
# Final generation